
摘要:本文探究了线性代数在计算机图形学中的应用,并进行了一些实践。
关键词:图像学,python,图像处理
引言:计算机图形处理基础概念
很多人不理解计算机学院在大一上期开展的线性代数课程,认为线性代数课程没有任何用途,只是拿来解方程而已。然而其实,在计算机图形学的领域,线性代数的作用其实超乎人的想象。 首先我们要理解的是,计算机如何“看”到图像。冲所周知,计算机没有“眼睛”,他也许看得见颜色美但是却无法理解。计算机看得懂的其实是数据,所以我们把一张图的每一个像素点的特征值提取出来,形成一个分辨率大小的矩阵,再传给计算机,计算机就可以理解。

那么,我们如何实现对一张图片的某些特征像素点进行操作呢?例如,在 PhotoShop 里我们可以调整一张图片的曝光,更改某个颜色区间的色调,这一切是怎么做到的呢? 如果我们把一张图片理解成一个矩阵,那么我们就可以对这个矩阵做矩阵操作,例如求特征值,矩阵乘法,矩阵数乘。矩阵乘法是一个向量的过程,他可以对举证数据的某一部分进行加权,这就是 “P” 图的基本原理。例如,假设我们想提取上面这张人脸的边框,我们可以将这个大矩阵卷积下面的这个 3x3 的小矩阵(矩阵1-1):
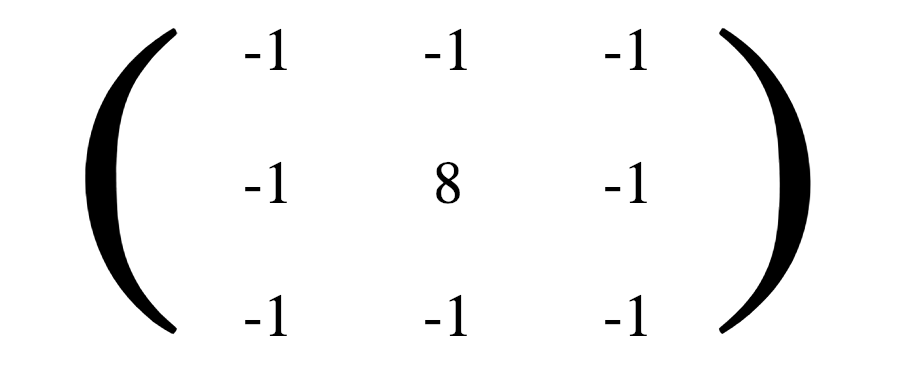
如果有一个全为1的 3x3 矩阵,来卷积上面的这个矩阵,我们可以得到下面的结果。


我们可以发现矩阵1-1的作用是提升中列的权重,降低两边列的权重,来增强边线的对比度,来提取边线。我们把这个矩阵用与整张图片可以得到一个效果非常好的边框提取图,把对比明显的界限全部提取了出来。
利用 Python 加深对计算机图像处理的理解
实践是最好的老师。最近发现四川大学的UPR综合教务系统新增了一个验 证码。本文将通过一系列操作来探究是否可以通过图像处理来处理噪化过的验证码图片,并进行识别。注意,下面所有的代码都引用了 Image 库和 pytesseract 库。
1
2
from PIL import Image
import pytesseract
首先我们从官方网站上得到一张验证码的图片。

可以看到学校验证码背景还是比较干净的。唯二的难点就是横跨验证码的一条黑色曲线与验证码字符的连接。我们可以发现,遮挡物是黑色的,背景是白到灰白的,而验证码是红色的,也就是说我们可以根据红色特征来二值化图片。为了准确找到红色的 RGB 值,我们先打印这张图片的直方图。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def main():
im = Image.open("2.jpg")
im = im.convert("P")
# im.show()
his = im.histogram()
print(his)
values = {}
for i in range(256):
values[i] = his[i]
for j, k in sorted(values.items(), key=lambda x: x[1], reverse=True)[:10]:
print(j, k)
if __name__ == '__main__':
main()
1
2
3
4
5
6
7
8
9
10
11
12
output:
[200, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 50, 19, 18, 91, 128, 8, 13, 1, 5, 19, 28, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 3, 4, 4, 34, 73, 4, 35, 11, 19, 104, 59, 1, 0, 5, 11, 5, 14, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 1, 6, 21, 10, 21, 0, 4, 72, 87, 133, 55, 0, 0, 135, 172, 16, 19, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 10, 18, 14, 0, 0, 86, 265, 193, 60, 0, 0, 2, 201, 41, 26, 0, 0, 0, 3, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 42, 38, 24, 0, 0, 0, 8, 2914, 542, 0, 0, 0, 5, 594, 947, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 401, 803, 0, 0, 0, 5, 918, 894, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
182 2915
189 974
224 943
225 923
219 819
188 557
183 487
218 388
139 261
0 234
output 中 的第一段是这张图的直方图,有180个元素。第2到第11行是直方图中值最高的10个颜色。我们可以根据这个数据来进行二值化。
1
2
3
4
5
6
7
8
im2 = Image.new("P", im.size, 255)
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y, x))
if pix > 120 or pix < 20: # these are the numbers to get
im2.putpixel((y, x), 0)
图片经过处理后可以得到这样的图像:


可以看到二值化还是比较成功的。接下来的我们想对中间的那条线在进行处理,目标是在验证码外面的 A 部分可以被填充为黑色,而验证码内部的 B 部分可以被填充为白色。要做到这个目标,我们首先需要把图片的边框全部填充为黑色,因为验证码不太可能出现在图片的边框上。
1
2
3
4
5
6
7
# clear boarder
for x in range(im.size[1]):
im2.putpixel((0,x), 0)
im2.putpixel((179,x), 0)
for y in range(im.size[0]):
im2.putpixel((y,0), 0)
im2.putpixel((y,59), 0)

然后,可以向目标进发了。我想的算法是这样的。每一次采样目标方块周围的8个方块中的颜色,如果8个方块中有7个以上为黑色,那么这个目标方块就被填充为黑色,否则就被填充为白色。如果只做一次上述操作的话,有时会遇见前面遍历的方块还没有处理完,后面的方块也无法正确判断的情况,所以我们将这个操作运行 8 次,得到的结果如下:

其实这样的处理结果,对于人而言已经很满意了。但是对于电脑而言,还不行。因为例如:5的上下部分断开了,d的小圈没有闭环。这些人眼虽然可以自动补全,但是对于电脑而言却是很难补全的错误。我们还需要想办法把断开的字母连上。有什么办法可以将白色辐射到周围的呢?可以遍历最小路径,但是我认为这个地方可以使用高斯模糊再二值化的操作。一整套流程下来是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
def fix(im, im2, n = 8):
for i in range(1, n):
for x in range(1, 59):
for y in range(1, 179):
pix1 = im2.getpixel((y - 1, x - 1))
pix2 = im2.getpixel((y - 1, x))
pix3 = im2.getpixel((y - 1, x + 1))
pix4 = im2.getpixel((y, x - 1))
pix5 = im2.getpixel((y, x + 1))
pix6 = im2.getpixel((y + 1, x - 1))
pix7 = im2.getpixel((y + 1, x))
pix8 = im2.getpixel((y + 1, x + 1))
blackcounter = 0
if (pix1 == 0):
blackcounter = blackcounter + 1
if (pix2 == 0):
blackcounter = blackcounter + 1
if (pix3 == 0):
blackcounter = blackcounter + 1
if (pix4 == 0):
blackcounter = blackcounter + 1
if (pix5 == 0):
blackcounter = blackcounter + 1
if (pix6 == 0):
blackcounter = blackcounter + 1
if (pix7 == 0):
blackcounter = blackcounter + 1
if (pix8 == 0):
blackcounter = blackcounter + 1
if blackcounter >= 7:
im2.putpixel((y, x), 0)
elif blackcounter <= 3:
im2.putpixel((y, x), 255)
for x in range(1, 59):
for y in range(1, 179):
pix1 = im2.getpixel((y - 1, x - 1))
pix2 = im2.getpixel((y - 1, x))
pix3 = im2.getpixel((y - 1, x + 1))
pix4 = im2.getpixel((y, x - 1))
pix5 = im2.getpixel((y, x + 1))
pix6 = im2.getpixel((y + 1, x - 1))
pix7 = im2.getpixel((y + 1, x))
pix8 = im2.getpixel((y + 1, x + 1))
pixvalue = pix1 + pix2 + pix3 + pix4 + pix5 + pix6 + pix7 + pix8
pixvalue = pixvalue / 8;
im2.putpixel((y, x), int(pixvalue))
for x in range(1,59):
for y in range(1,179):
pix = im2.getpixel((y, x))
if pix < 120: # these are the numbers to get
im2.putpixel((y, x), 0)
else:
im2.putpixel((y,x), 255)
得到的目标图像如下:

这之后,再对图片做 OCR 识别应该就比较好了。受限于 pytessert 的 OCR 识别率极低,但又是唯一开源的 OCR 识别系统,所以在本次实践中无法正确识别出验证码。但我相信如果根据处理后结果训练一个模型,那识别率至少可以高于60%。
完整源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
from PIL import Image
import pytesseract
def fix(im, im2, n = 8):
for i in range(1, n):
for x in range(1, 59):
for y in range(1, 179):
pix1 = im2.getpixel((y - 1, x - 1))
pix2 = im2.getpixel((y - 1, x))
pix3 = im2.getpixel((y - 1, x + 1))
pix4 = im2.getpixel((y, x - 1))
pix5 = im2.getpixel((y, x + 1))
pix6 = im2.getpixel((y + 1, x - 1))
pix7 = im2.getpixel((y + 1, x))
pix8 = im2.getpixel((y + 1, x + 1))
blackcounter = 0
if (pix1 == 0):
blackcounter = blackcounter + 1
if (pix2 == 0):
blackcounter = blackcounter + 1
if (pix3 == 0):
blackcounter = blackcounter + 1
if (pix4 == 0):
blackcounter = blackcounter + 1
if (pix5 == 0):
blackcounter = blackcounter + 1
if (pix6 == 0):
blackcounter = blackcounter + 1
if (pix7 == 0):
blackcounter = blackcounter + 1
if (pix8 == 0):
blackcounter = blackcounter + 1
if blackcounter >= 7:
im2.putpixel((y, x), 0)
elif blackcounter <= 3:
im2.putpixel((y, x), 255)
for x in range(1, 59):
for y in range(1, 179):
pix1 = im2.getpixel((y - 1, x - 1))
pix2 = im2.getpixel((y - 1, x))
pix3 = im2.getpixel((y - 1, x + 1))
pix4 = im2.getpixel((y, x - 1))
pix5 = im2.getpixel((y, x + 1))
pix6 = im2.getpixel((y + 1, x - 1))
pix7 = im2.getpixel((y + 1, x))
pix8 = im2.getpixel((y + 1, x + 1))
pixvalue = pix1 + pix2 + pix3 + pix4 + pix5 + pix6 + pix7 + pix8
pixvalue = pixvalue / 8;
im2.putpixel((y, x), int(pixvalue))
for x in range(1,59):
for y in range(1,179):
pix = im2.getpixel((y, x))
if pix < 120: # these are the numbers to get
im2.putpixel((y, x), 0)
else:
im2.putpixel((y,x), 255)
def main():
im = Image.open("captcha.jpg")
im = im.convert("P")
# im.show()
his = im.histogram()
print(his)
values = {}
for i in range(256):
values[i] = his[i]
for j, k in sorted(values.items(), key=lambda x: x[1], reverse=True)[:10]:
print(j, k)
im2 = Image.new("P", im.size, 255)
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y, x))
if pix > 120 or pix < 20: # these are the numbers to get
im2.putpixel((y, x), 0)
#im2.show()
# clear boarder
for x in range(im.size[1]):
im2.putpixel((0,x), 0)
im2.putpixel((179,x), 0)
for y in range(im.size[0]):
im2.putpixel((y,0), 0)
im2.putpixel((y,59), 0)
#im2.show()
# fix
fix(im, im2, 8)
im2.show()
print(pytesseract.image_to_string(im2, lang="eng"))
if __name__ == '__main__':
main()
总结:
我们可以看到,如果说我们日常学习的算法是告诉计算机“怎么算”,那么图像学就是告诉计算机“怎么看”“怎么联想”。计算机的图像学是一门非常深的学问,但也是非常有意思的。
参考文献:
Setosa data visualization and visual explanations http://setosa.io/ev/image-kernels/
本文作者 Auther:Soptq
本文链接 Link: https://soptq.me/2018/12/20/machine-eyes/
版权声明 Copyright: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处。 Content on this site is licensed under the CC BY-NC-SA 4.0 license agreement unless otherwise noted. Attribution required.
发现存在错别字或者事实错误?请麻烦您点击 这里 汇报。谢谢您!