
上篇文章之后我又去训练了一个可以识别动漫人物脸部和脸部关键点的模型,自我感觉挺不错的,不像是以前我写的那种见不得人的优(la)秀(ji)代码,再联想到谷歌家的 Tensorflow.js,就萌发了做一个在线 demo 的想法。结果我没有想到 TensorFlow.js 的部署实在是太坑了,文档少不说,还很不全面,整个过程非常的坎坷。但万幸最后还是做出来了,特别献出这篇博文,为以后某些想要线上部署深度学习模型的人指明一条可能行得通的道路。
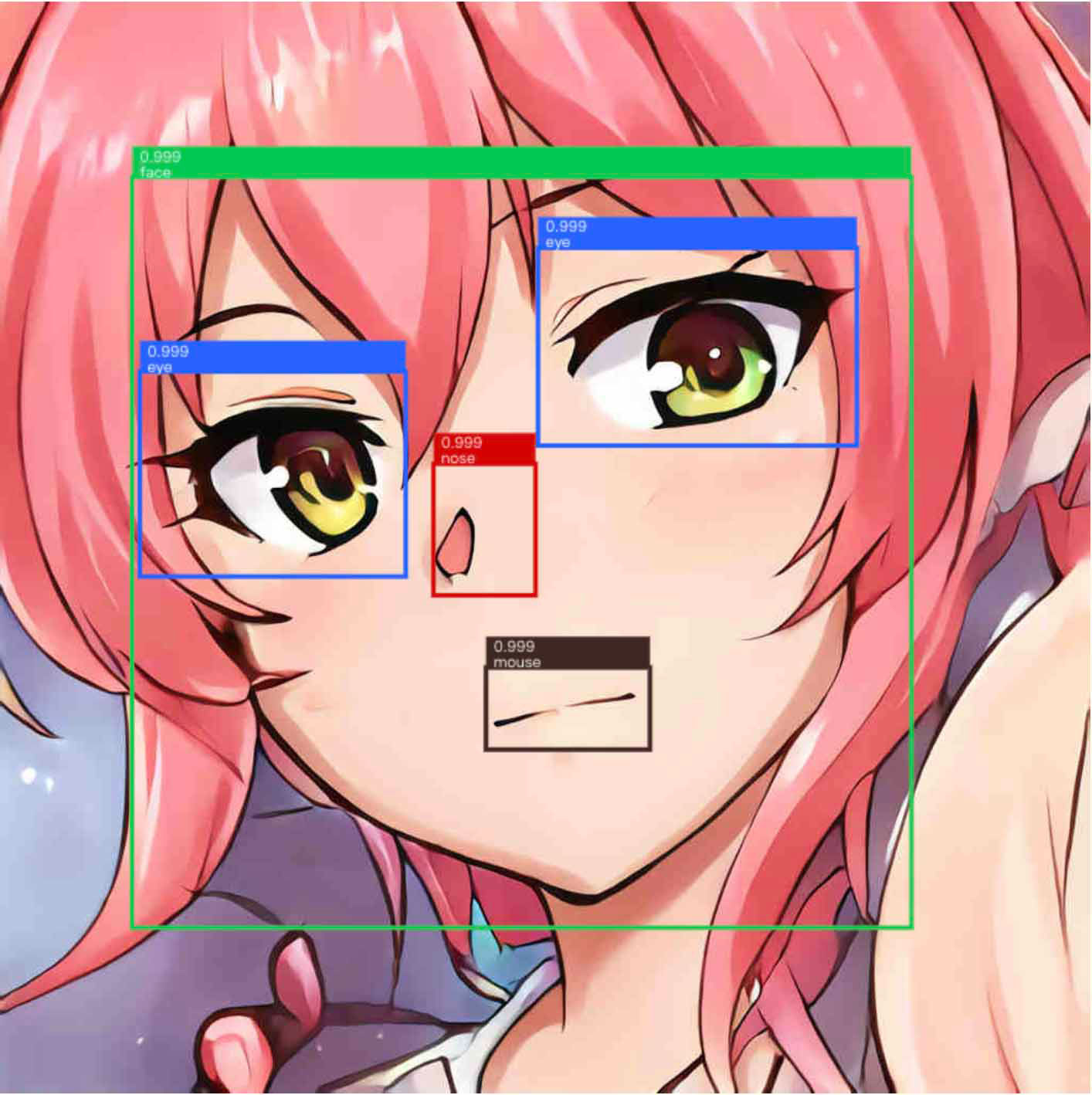
是 mouth 不是 mouse …
大前提:
本文中我想要部署的模型是 SSD_MobileNetV2_CoCo object_detection 模型,最后实现的效果 Waifu_Recognition Demo
准备环境
一行代码解决问题
1
pip install tensorflowjs
写这篇文章时, tensorflowjs 的版本为 0.8.0
模型转换
毕竟轻量级的使用,几百兆的模型部署到网站上还是很不好的。tensorflow_converter 在 1.0.0 之前还支持 Frozen Model (*.pb) 的转换,但是 1.0.0 后已经不支持了,所以我推荐导出模型的时候导出为 SavedModel 形式。其他目前支持的格式有 Tensorflow Hub , Keras h5 , tf.keras SavedModel 。如果是用谷歌的 object_detection_api 的话,先用 tensorflow/research/object_detection 下的 export_inference_graph.py 1导出,然后在到处文件夹中可以看到 saved model 文件夹,里面就是 SavedModel。本文以 SavedModel 为例子进行转换。
1
2
3
4
5
6
tensorflowjs_converter \
--input_format=tf_saved_model \
--output_node_names='Postprocessor/ExpandDims_1,Postprocessor/Slice' \
--saved_model_tags=serve \
input/waifu_recognition/saved_model \
input/waifu_recognition/web_model
最后两行为输入文件夹和输出文件夹。对于 object_detection 模型最坑的地方是 --output_node_names 不能为 "MobilenetV2/Predictions/Reshape_1" 或者其他的什么。因为 tensorflow.js 没有办法处理 PostProcessing 过程,也就是直接输出预测的结果,只能输出到预测的矩阵位置向量和预测的矩阵分类向量,否则就会报错。所以对于 object_detection,这个地方要改为 "ostprocessor/ExpandDims_1,Postprocessor/Slice"2。
还有就是这个转换命令,必须需要 GPU 的 cuDNN 加速3。
运行完成后,你会得到一个文件夹里包含一个 tensorflowjs_model.pb 文件,一个 weights_manifest.json 文件,和若干个 group1-shard1of5 文件。这些生成的东西以后可能会发生更改4,一切以你使用的 tensorflowjs_converter 版本为准。
部署
依赖
1
2
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@0.13.5/dist/tf.js"> </script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter@0.8.0/dist/tf-converter.js"></script>
加载模型
1
2
3
4
5
const MODEL_URL = 'web_model/tensorflowjs_model.pb';
const WEIGHTS_URL = 'web_model/weights_manifest.json';
async function object_detection(img){
const model = await tf.loadFrozenModel(MODEL_URL, WEIGHTS_URL);
}
准备样本
1
<img id="img" class="demo-image" src="/waifu_recognition_demo/images/image-1.jpg" alt="image" />
将样本传给模型
1
2
3
4
img = document.getElementById('img');
const image = tf.fromPixels(img);
const pixels = image.reshape([1, ...image.shape]);
const executeresult = model.executeAsync(pixels);
得到的 executeresult 大概是这样的
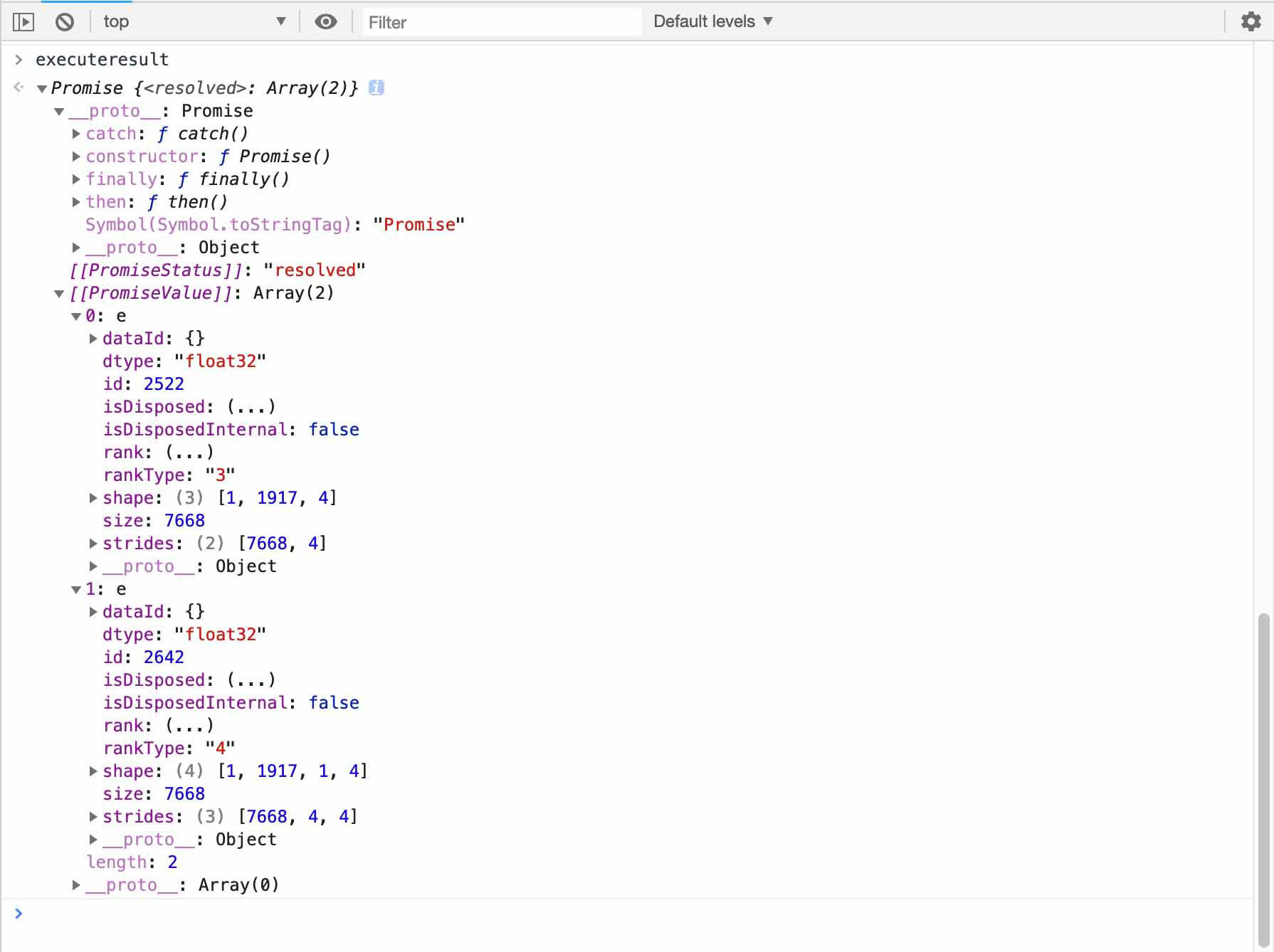
那么将这些数据用 javascript 转换为我们想要的预测结果,就是我们接下来要做的工作了。
手动 PostProcessing
calculateMaxScores 函数
这个函数的作用是在一大堆可能的结果中选择最有可能的结果,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
function calculateMaxScores(scores , numBoxes, numClasses) {
const maxes = [];
const classes = [];
for (let i = 0; i < numBoxes; i++) {
let max = Number.MIN_VALUE;
let index = -1;
for (let j = 0; j < numClasses; j++) {
if (scores[i * numClasses + j] > max) {
max = scores[i * numClasses + j];
index = j;
}
}
maxes[i] = max;
classes[i] = index;
}
return [maxes, classes];
}
buildDetectedObjects 函数
这个函数的作用就是将最有可能的结果归类打包成一个数组。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
function getDisplayName(i) {
switch (i) {
case 0:
return "face";
case 1:
return "eye";
case 2:
return "nose";
case 3:
return "mouse";
}
}
function buildDetectedObjects(width, height, boxes, scores, indexes, classes){
const count = indexes.length;
const objects = [];
for (let i = 0; i < count; i++) {
const bbox = [];
for (let j = 0; j < 4; j++) {
bbox[j] = boxes[indexes[i] * 4 + j];
}
const minY = bbox[0] * height;
const minX = bbox[1] * width;
const maxY = bbox[2] * height;
const maxX = bbox[3] * width;
bbox[0] = minX;
bbox[1] = minY;
bbox[2] = maxX - minX;
bbox[3] = maxY - minY;
objects.push({
bbox: bbox,
class: getDisplayName(classes[indexes[i]]),
score: scores[indexes[i]]
});
}
console.log(objects);
PREDICTION = objects;
return objects;
}
drawRendered 函数
这个函数的作用是将上一个函数的到的结果使用 canvas 画出来,画的位置是一个和 img 一样位置的 canvas,这样就可以模拟直接画在图片上的样子了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
function getClass(str) {
if (str === 'face'){
return 0;
} else if (str === 'eye'){
return 1;
}else if (str === 'nose') {
return 2;
}else if (str === 'mouse'){
return 3;
}
}
function drawRendered(img, canvas){
colorList = ["#00c853", "#2962ff", "#d50000", "#3e2723"];
const length = PREDICTION.length;
for (let i = 0; i < length; i++){
ctx.beginPath();
ctx.rect(PREDICTION[i]["bbox"][0], PREDICTION[i]['bbox'][1], PREDICTION[i]["bbox"][2], PREDICTION[i]["bbox"][3]);
ctx.lineWidth = 3;
ctx.strokeStyle = colorList[getClass(PREDICTION[i]['class'])];
ctx.stroke();
ctx.beginPath();
ctx.fillStyle = colorList[getClass(PREDICTION[i]['class'])];
ctx.fillRect(PREDICTION[i]["bbox"][0], PREDICTION[i]['bbox'][1], PREDICTION[i]["bbox"][2], -20);
ctx.stroke();
ctx.font = "10px sans-serif";
ctx.fillStyle = "#FFFFFF";
ctx.fillText(PREDICTION[i]['class'], PREDICTION[i]["bbox"][0] + 5, PREDICTION[i]['bbox'][1]);
ctx.fillText(PREDICTION[i]['score'].toString().substring(0,5), PREDICTION[i]["bbox"][0] + 5, PREDICTION[i]['bbox'][1] - 10);
}
}
全部 JS 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
const MODEL_URL = 'web_model/tensorflowjs_model.pb';
const WEIGHTS_URL = 'web_model/weights_manifest.json';
img = document.getElementById('img');
canvas = document.getElementById('canvas');
//将 canvas 的位置置于 img 上面
canvas.style.position = "absolute";
canvas.style.left = img.offsetLeft + "px";
canvas.style.top = img.offsetTop + "px";
canvas.width = img.width;
canvas.height = img.height;
var ctx = canvas.getContext("2d");
var PREDICTION = []; //全局变量,用来存储预测结果
function calculateMaxScores(scores , numBoxes, numClasses) {
const maxes = [];
const classes = [];
for (let i = 0; i < numBoxes; i++) {
let max = Number.MIN_VALUE;
let index = -1;
for (let j = 0; j < numClasses; j++) {
if (scores[i * numClasses + j] > max) {
max = scores[i * numClasses + j];
index = j;
}
}
maxes[i] = max;
classes[i] = index;
}
return [maxes, classes];
}
function getDisplayName(i) {
switch (i) {
case 0:
return "face";
case 1:
return "eye";
case 2:
return "nose";
case 3:
return "mouse";
}
}
function getClass(str) {
if (str === 'face'){
return 0;
} else if (str === 'eye'){
return 1;
}else if (str === 'nose') {
return 2;
}else if (str === 'mouse'){
return 3;
}
}
function buildDetectedObjects(width, height, boxes, scores, indexes, classes){
const count = indexes.length;
const objects = [];
for (let i = 0; i < count; i++) {
const bbox = [];
for (let j = 0; j < 4; j++) {
bbox[j] = boxes[indexes[i] * 4 + j];
}
const minY = bbox[0] * height;
const minX = bbox[1] * width;
const maxY = bbox[2] * height;
const maxX = bbox[3] * width;
bbox[0] = minX;
bbox[1] = minY;
bbox[2] = maxX - minX;
bbox[3] = maxY - minY;
objects.push({
bbox: bbox,
class: getDisplayName(classes[indexes[i]]),
score: scores[indexes[i]]
});
}
console.log(objects);
PREDICTION = objects;
return objects;
}
async function object_detection(img){
const maxNumBoxes = 20;
const model = await tf.loadFrozenModel(MODEL_URL, WEIGHTS_URL);
const image = tf.fromPixels(img);
const pixels = image.reshape([1, ...image.shape]);
const executeresult = model.executeAsync(pixels);
const height = image.shape[0];
const width = image.shape[1];
executeresult.then(function(value){
tensorarray = value;
const scores = tensorarray[0].dataSync();
const boxes = tensorarray[1].dataSync();
const [maxScores, classes] = this.calculateMaxScores(scores, tensorarray[0].shape[1], tensorarray[0].shape[2]);
const prevBackend = tf.getBackend();
ntf.setBackend('cpu');
const indexTensor = tf.tidy(() => {
const boxes2 =
tf.tensor2d(boxes, [tensorarray[1].shape[1], tensorarray[1].shape[3]]);
return tf.image.nonMaxSuppression(
boxes2, maxScores, maxNumBoxes, 0.5, 0.5);
});
const indexes = indexTensor.dataSync();
indexTensor.dispose();
// restore previous backend
tf.setBackend(prevBackend);
this.buildDetectedObjects(width, height, boxes, maxScores, indexes, classes);
drawRendered(img, canvas);
return PREDICTION
}, function(error){});
}
function drawRendered(img, canvas){
colorList = ["#00c853", "#2962ff", "#d50000", "#3e2723"];
const length = PREDICTION.length;
for (let i = 0; i < length; i++){
ctx.beginPath();
ctx.rect(PREDICTION[i]["bbox"][0], PREDICTION[i]['bbox'][1], PREDICTION[i]["bbox"][2], PREDICTION[i]["bbox"][3]);
ctx.lineWidth = 3;
ctx.strokeStyle = colorList[getClass(PREDICTION[i]['class'])];
ctx.stroke();
ctx.beginPath();
ctx.fillStyle = colorList[getClass(PREDICTION[i]['class'])];
ctx.fillRect(PREDICTION[i]["bbox"][0], PREDICTION[i]['bbox'][1], PREDICTION[i]["bbox"][2], -20);
ctx.stroke();
ctx.font = "10px sans-serif";
ctx.fillStyle = "#FFFFFF";
ctx.fillText(PREDICTION[i]['class'], PREDICTION[i]["bbox"][0] + 5, PREDICTION[i]['bbox'][1]);
ctx.fillText(PREDICTION[i]['score'].toString().substring(0,5), PREDICTION[i]["bbox"][0] + 5, PREDICTION[i]['bbox'][1] - 10);
}
}
function predict(){
object_detection(img)
}
结束
不出意外的话这样下来你就可以看到自己的模型预测的结果了。如果这篇文章可以帮助的了你的话,我也终于可以安心流下了心酸的泪水了。
Q&A
Q: 载入模型失败?
A: 检查一下模型的地址必须是 url (http://…. 这种),不能是相对地址啊那些。
Q: Failed to execute ‘texImage2D’ on ‘WebGL2RenderingContext’: The image element contains cross-origin data, and may not be loaded.
A: 简单的说就是如果你 tf.fromPixels(img) 这个 img 的地址域名不是你自己网站的域名,被安全协议禁止了。
Q: … has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource
A: 跟上面那个有点像。你试图加载的 url 的服务器域名与你的服务器域名不一致,而 url 服务器又没有特别允许你可以去它的服务器内部,所以就被游览器禁止了。这个问题我也找了很久解决方案,本来是想从其他服务器去拿测试图片,可就触发了这个安全协议,最后还是只能在我自己的网站上存一些测试图片。
本文作者 Auther:Soptq
本文链接 Link: https://soptq.me/2019/03/09/set-up-tfjs/
版权声明 Copyright: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处。 Content on this site is licensed under the CC BY-NC-SA 4.0 license agreement unless otherwise noted. Attribution required.
发现存在错别字或者事实错误?请麻烦您点击 这里 汇报。谢谢您!